🎬AI Lectures15
Difficulty:
 LLM
LLMStanford CS336 Language Modeling from Scratch | Spring 2025 | Lecture 13: Data 1
IntermediateStanford Online
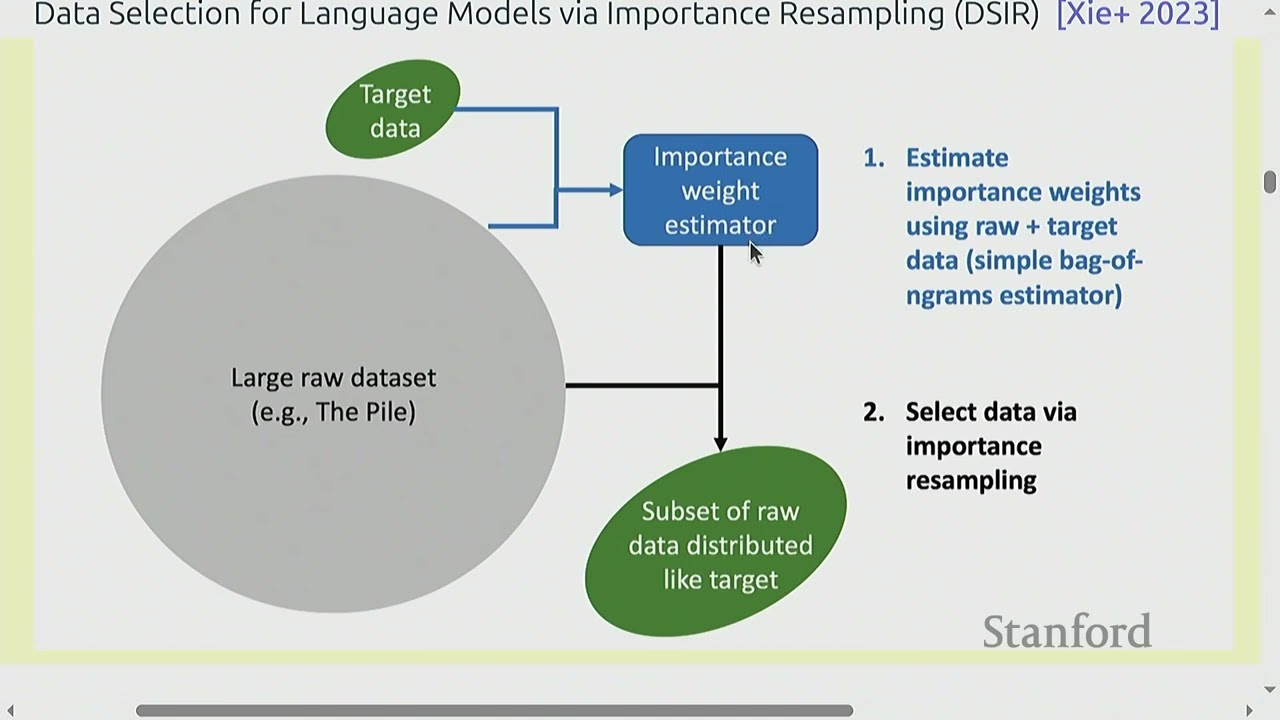
This class explains why data is the most important part of building language models. You learn where text data comes from (books, the web, and human feedback) and what each source is good and bad at. The instructor stresses that most of your time in real projects goes into finding, collecting, cleaning, and filtering data, not model code.
#common crawl#c4#mc4